 たまこじブログ
たまこじブログ 

データ分析の世界へ足を踏み入れたばかりの皆さん、ようこそ!集めたデータをただ眺めているだけでは、その全体像を把握するのは難しいですよね。そんな時、強力な味方となるのがグラフによるデータ可視化です!この記事では、PythonのSeabornライブラリに搭載された便利な関数、histplotを使って、データの分布を誰にでも分かりやすく描画する方法を、初心者の方に向けて丁寧に解説します。ヒストグラムの作成方法をマスターして、データとの対話をより深く、より豊かなものにしましょう!
Seabornは、Pythonでグラフを描画するための基本となるMatplotlibというライブラリを、さらに使いやすく、そして洗練されたデザインにしたようなライブラリです。特に、データ分析でよく使うPandasのDataFrameというデータ形式と非常に相性が良く、データの整理からグラフの作成までをスムーズに進めることができます。

データ分布とは、集めたデータがどのような値の範囲に、どれくらいの頻度で現れているかを示すものです。例えば、テストの点数であれば、「50点台の人が多いな」とか「90点以上の人もいるんだ」といった具合に、データの散らばり具合を見るイメージです。このデータの散らばり具合を、棒グラフで分かりやすく表現したものがヒストグラムなのです。
ヒストグラムでは、データをいくつかの区間(ビンと呼びます)に分け、それぞれの区間にデータがいくつ入っているかを、棒の高さで示します。「この値の範囲には、データがたくさんあるんだな〜」とか、「この範囲には、あまりデータがないんだな〜」ということが、一目で分かりますよね!
ヒストグラムを使うと、以下のことが分かります。
- データ全体の分布: 値の範囲を視覚的に把握
- 中心傾向: 最頻値や中央値を特定
- データのばらつき: データの集中度合いを評価
- 外れ値の検出: 異常な値を特定
- 多峰性: データのグループ構造を発見
これらの情報を得ることで、データに対する理解が深まり、次の分析に進むためのヒントが見つかることもあるのです。

それでは早速、Seabornでヒストグラムを描画してみましょう!最も簡単な方法は、histplot関数を使うことです。まずは、お決まりとして、必要なライブラリをインポートします。そして今回は、Seabornが用意してくれている、アヤメのデータセット(irisデータセット)を使ってみますね!
import seaborn as sns
import matplotlib.pyplot as plt # グラフを画面に表示するために必要
# サンプルデータとしてSeabornに用意されているirisデータセットを読み込む
data = sns.load_dataset('iris')
# 'sepal_length'(がく片の長さ)のヒストグラムを描画
sns.histplot(data=data, x='sepal_length')
# グラフを表示
plt.show()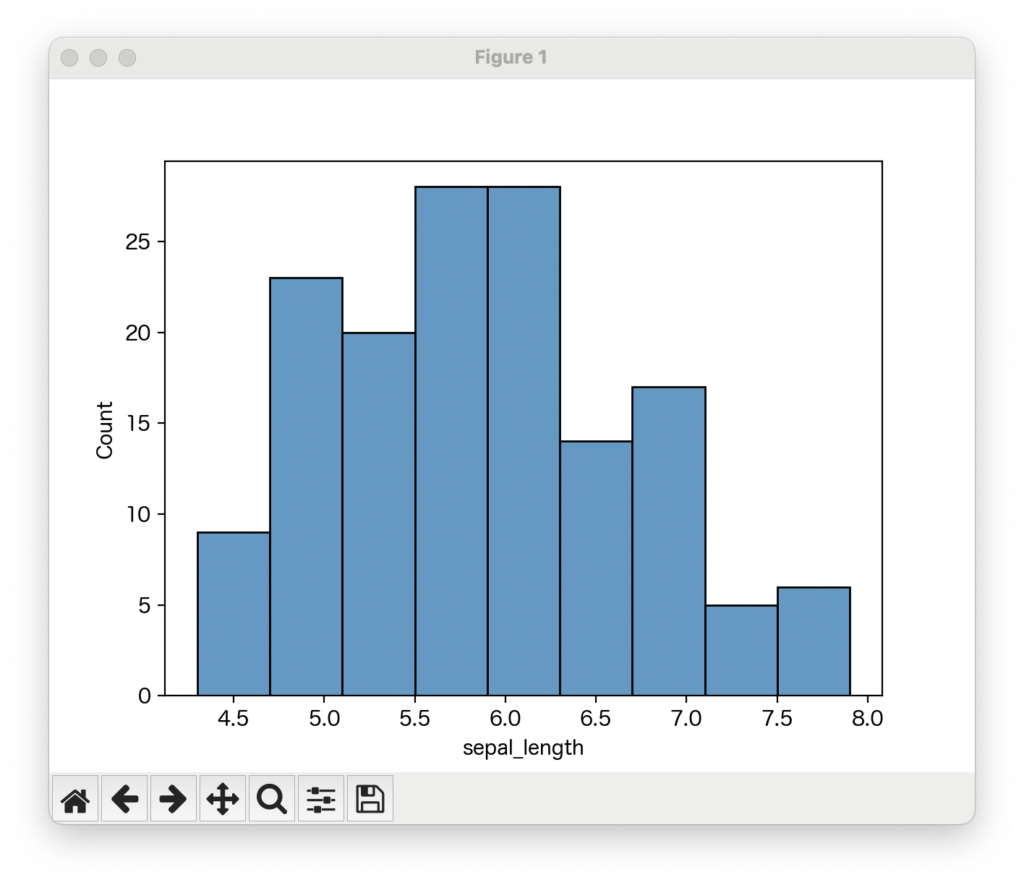
このコードを実行すると、irisデータセットに含まれるsepal_length(がく片の長さ)というデータの分布が、棒グラフで表示されます。「へぇ、こんな形をしているんだ!」と、きっと新たな発見があるでしょう!
histplot関数を使う際に、覚えておきたい基本的なパラメータは、この2つです。
data: どのデータを使用するかを指定します。ここでは、irisデータセットを読み込んだdataという変数を指定しています。Seabornでは、PandasのDataFrameという形式でデータを扱うことが多いので、覚えておくと便利です。PandasのDataFrameを使うと、データの整理もグラフの作成も、とても簡単になります。x: ヒストグラムの横軸に、どのデータの列を表示したいかを指定します。ここでは、'sepal_length'(がく片の長さ)という列の名前を指定しています。どの数値データの分布を見たいかを指定するために、xパラメータは必須です。
基本的なヒストグラムが描けるようになったら、次はより多くのオプションを試してみましょう!histplot関数には、さらに詳しくデータを分析したり、グラフを見やすくするための、多くの便利な機能が用意されています。
もしデータの中に、何らかのカテゴリ分けができる列(例えば、性別や地域など)がある場合、hueパラメータを使うと、そのカテゴリごとにヒストグラムの色を分けて表示することができます。irisデータセットには、アヤメの種類を示す'species'という列があるので、これを使って、種類ごとにがく片の長さの分布を比較してみましょう。
import seaborn as sns
import matplotlib.pyplot as plt
data = sns.load_dataset('iris')
# 'species'(アヤメの種類)ごとに'sepal_length'のヒストグラムを描画し、色分け
sns.histplot(data=data, x='sepal_length', hue='species')
plt.show()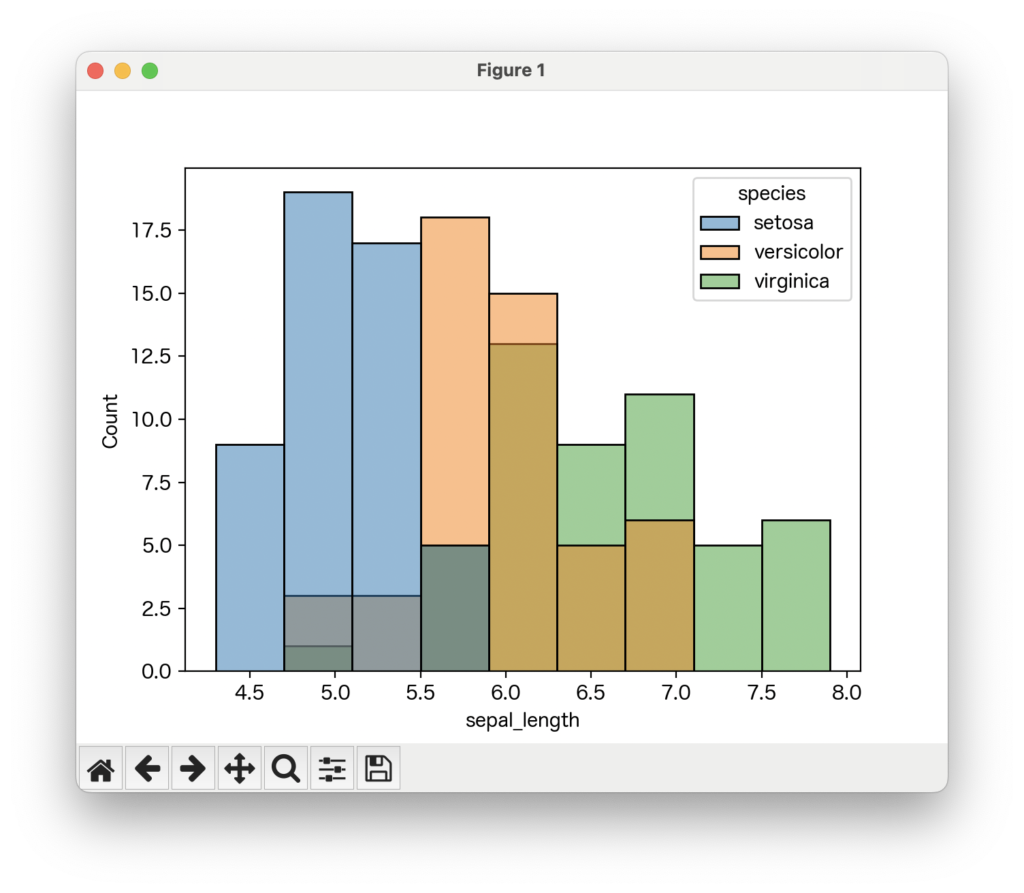
このコードを実行すると、アヤメの種類(setosa、versicolor、virginica)ごとに、異なる色のヒストグラムが表示されます。それぞれの種類で、がく片の長さの分布がどのように異なるのかを、一目で確認できますね!
さらに、hueパラメータと一緒に使うと便利なのがmultipleパラメータです。これは、複数のヒストグラムをどのように表示するかを指定するもので、重ねて表示したり、横に並べて表示したりできます ('layer', 'stack', 'dodge', 'fill' など)。
例えば、multiple='dodge'を指定すると、同じ値の範囲にある異なる種類の棒が横に並んで表示されるため、それぞれの種類の頻度を比較しやすくなります。
import seaborn as sns
import matplotlib.pyplot as plt
data = sns.load_dataset('iris')
# 'species'ごとに'sepal_length'のヒストグラムを横に並べて表示
sns.histplot(data=data, x='sepal_length', hue='species', multiple='dodge')
plt.show()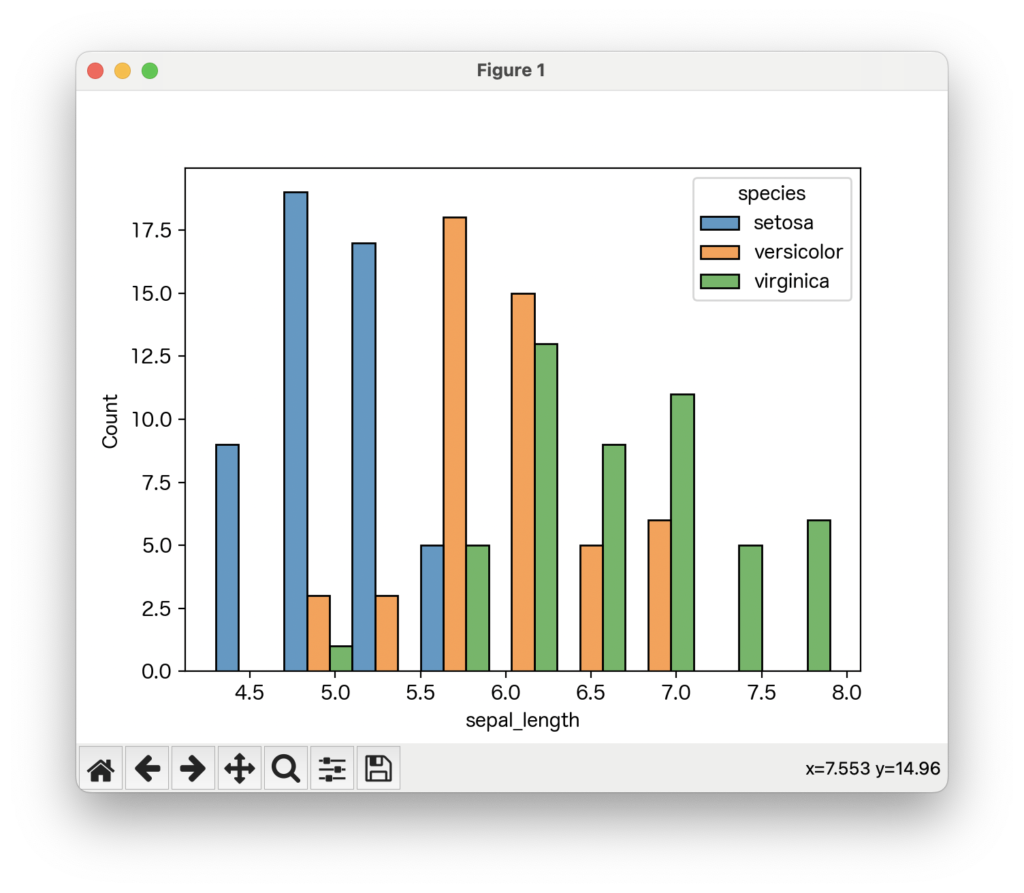
statパラメータを使うと、各ビンの中でどのような値を集計して表示するかを選ぶことができます。デフォルトでは、各ビンに入っているデータの数を数える 'count' が設定されていますが、他の集計方法も選択できます。
'frequency':各ビンに入っているデータの数を、そのビンの幅で割った値を表示します 。'probability'または'proportion':各棒の高さの合計が1になるように、データの割合を表示します 。'percent':各棒の高さの合計が100になるように、データの割合をパーセントで表示します 。'density':ヒストグラム全体の面積が1になるように、データの密度を表示します 。
例えば、'probability'を指定すると、各ビンに含まれるデータの割合が表示されます。データ全体の傾向を比較したい場合に便利です。
import seaborn as sns
import matplotlib.pyplot as plt
data = sns.load_dataset('iris')
# 'sepal_length'のヒストグラムを確率で表示
sns.histplot(data=data, x='sepal_length', stat='probability')
plt.show()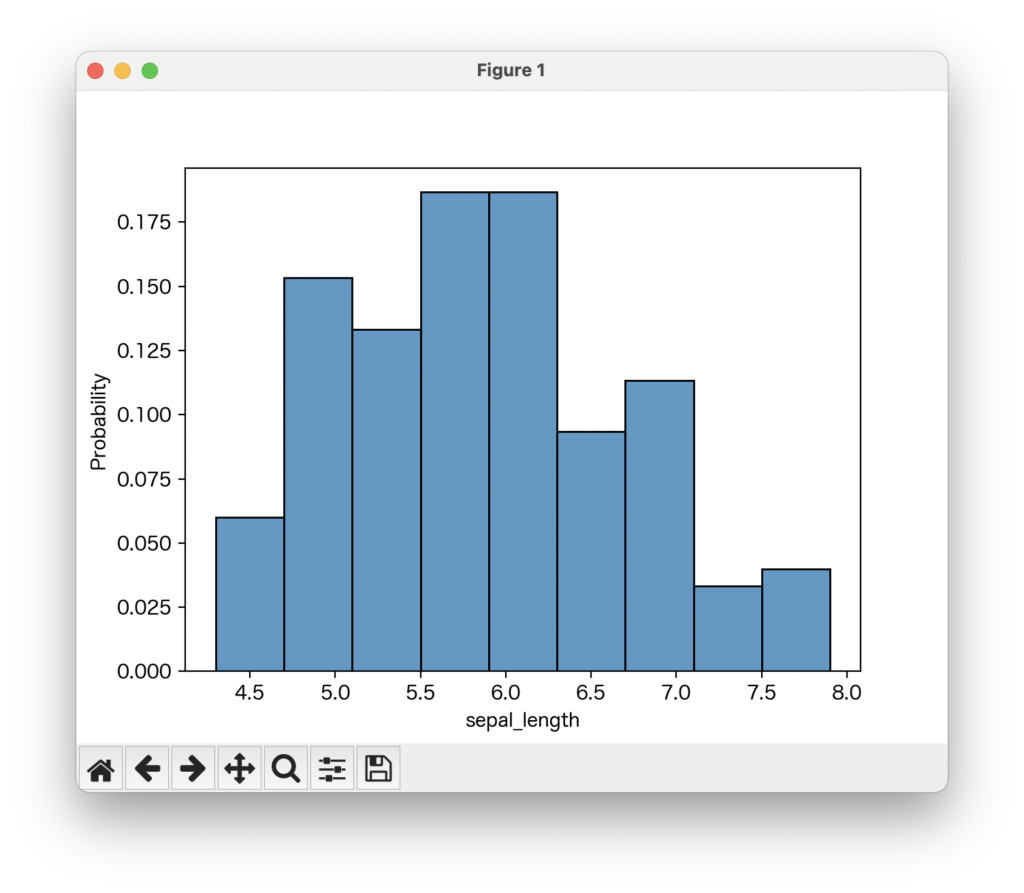
ヒストグラムの棒の数や幅を調整することで、データの分布の見え方が変わることがあります。binsパラメータで棒の数を指定したり、binwidthパラメータで各棒の幅を直接指定したりできます。
import seaborn as sns
import matplotlib.pyplot as plt
data = sns.load_dataset('iris')
# ビンの数を20に指定
sns.histplot(data=data, x='sepal_length', bins=20)
plt.show()
# ビンの幅を0.5に指定
sns.histplot(data=data, x='sepal_length', binwidth=0.5)
plt.show()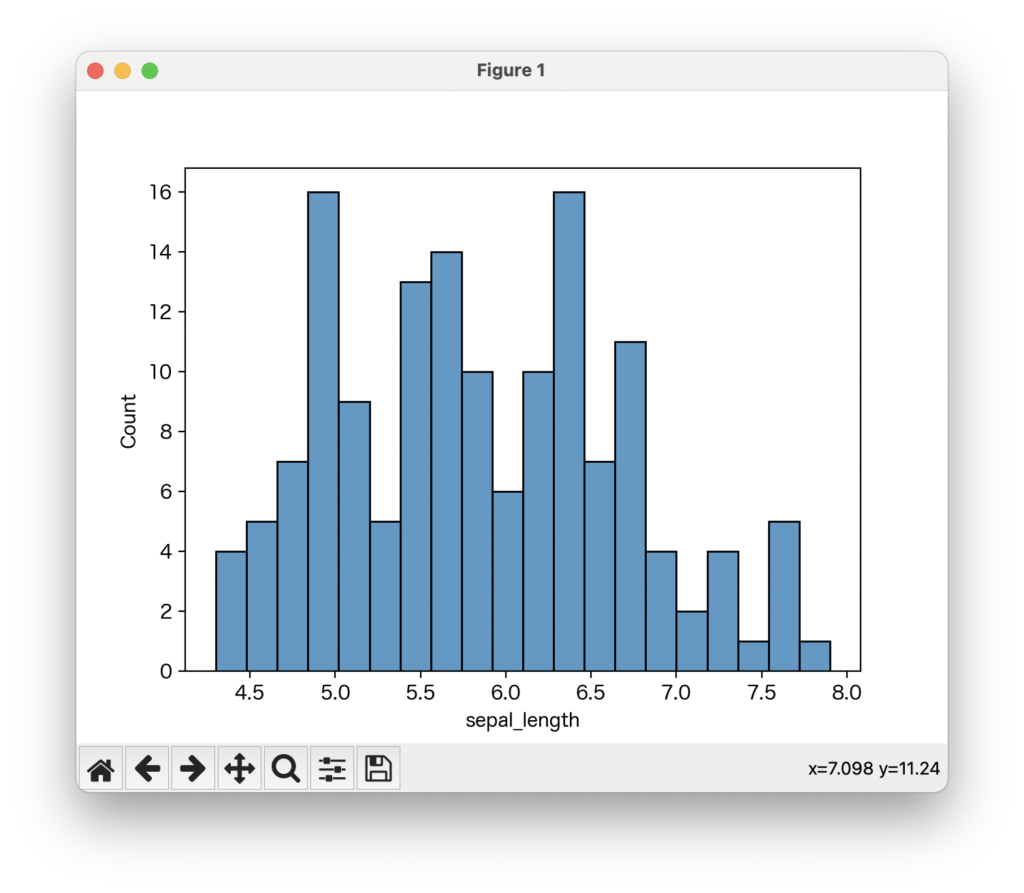
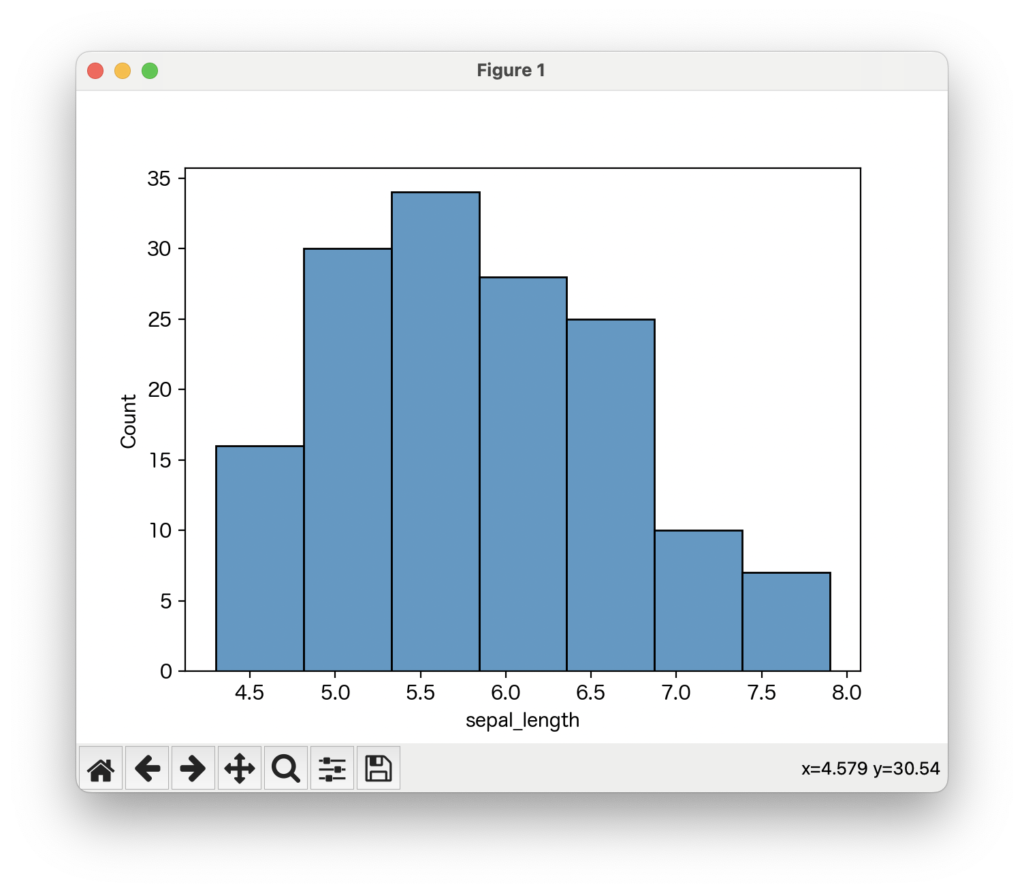
棒の数を変えてみると、データの細かな動きが見えたり、逆に大まかな全体像が見えたりします。色々と試してみることをお勧めします。
kde=Trueと設定すると、ヒストグラムの上にカーネル密度推定(KDE)という、データの分布を滑らかに表現した線が重ねて表示されます。データの分布の形状を、より滑らかに把握したい場合に便利です。
import seaborn as sns
import matplotlib.pyplot as plt
data = sns.load_dataset('iris')
# 'sepal_length'のヒストグラムにKDEプロットを重ねて表示
sns.histplot(data=data, x='sepal_length', kde=True)
plt.show()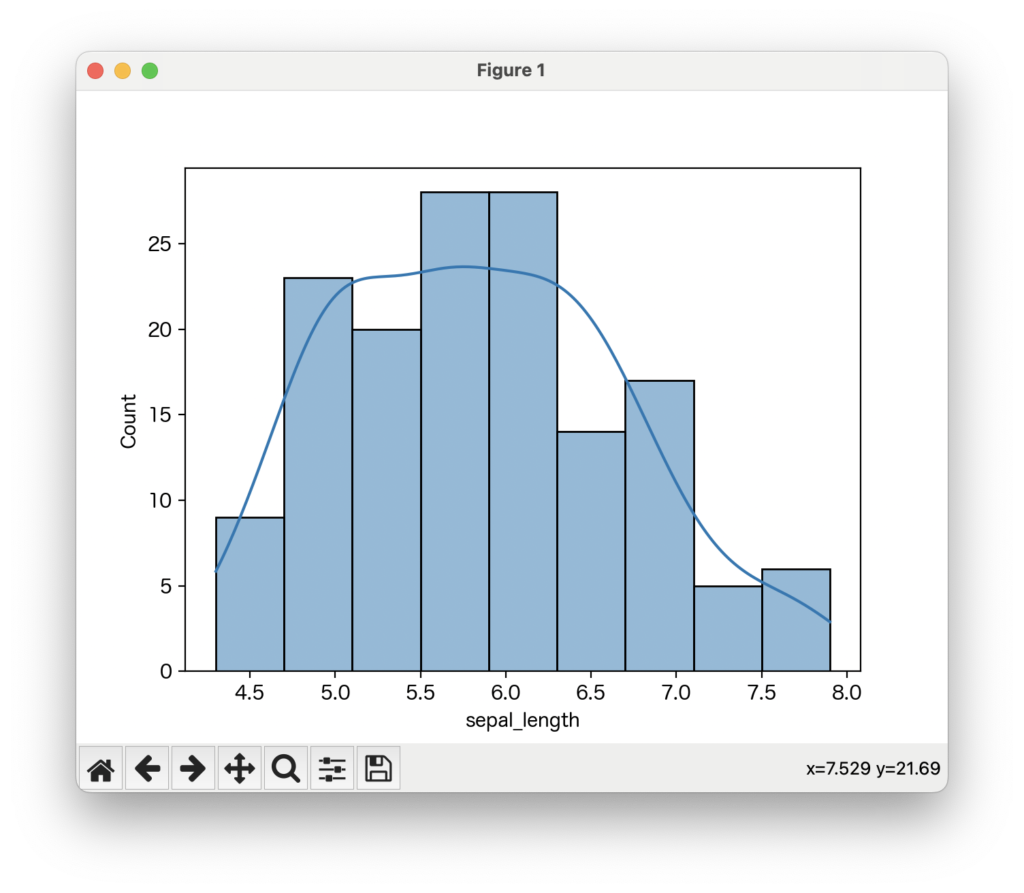
KDEプロットを重ねることで、ヒストグラムの棒だけでは少しごつごつして見える分布を、より滑らかに捉えることができます。
histplot関数には、他にもグラフの見た目を細かく調整できるパラメータがたくさんあります。
color: 棒の色を指定できます 。alpha: 棒の透明度を指定できます (0から1の間の値で、0に近いほど透明になります) 。element: 棒の表示方法を、通常の棒グラフだけでなく、線のグラフ ('step') や、棒の中心を結んだ多角形 ('poly') に変更できます 。fill: 棒を塗りつぶすかどうかを指定できます (Trueで塗りつぶし、Falseで輪郭だけになります) 。
これらのパラメータを色々試して、自分が見やすく、そして伝えたいことが伝わるヒストグラムを作成してみてくださいね!
今回の記事では、PythonのSeabornライブラリのhistplot関数を使って、データの分布を簡単に可視化する方法を解説しました。histplot関数は、多くのパラメータを調整することで、データの特性や分析の目的に合わせたヒストグラムを、初心者でも簡単に作成できる強力なツールです。
今回ご紹介したパラメータ以外にも、histplot関数にはまだまだ多くの機能が備わっています。Seabornの公式ドキュメント や、様々な情報源 を参考に、ぜひ皆さんの持っているデータでhistplotを試して、データに対する理解を深めてみてください!きっと、今まで見えなかった新しい発見があるはずですよ!
おつー
ミニストップのあの味が、おうちで楽しめる!公式ストアが便利すぎる
ミニストップで大人気の「クランキーチキン」や「Xフライドポテト」が、冷凍でおうちに届くのをご存知ですか? おつまみやお子さまのおやつにストックしておけば、いつでも揚げたての美味しさが楽しめます。
見逃せないのが「訳あり商品」! 賞味期限間近や規格外のアイテムが随時追加され、驚きのオトク価格でゲットできるチャンスも。
さらに、重い飲料・お酒のケース販売も送料無料。季節のケーキや限定キャラクターグッズの「店頭受取予約」も可能です。 定期的なセールも開催されているので、まずは今のセール情報をチェックしてみてください!


